
For today’s blog entry I will combine both Cloud and Big Data to show you how easy it is to do Big Data on the Cloud.
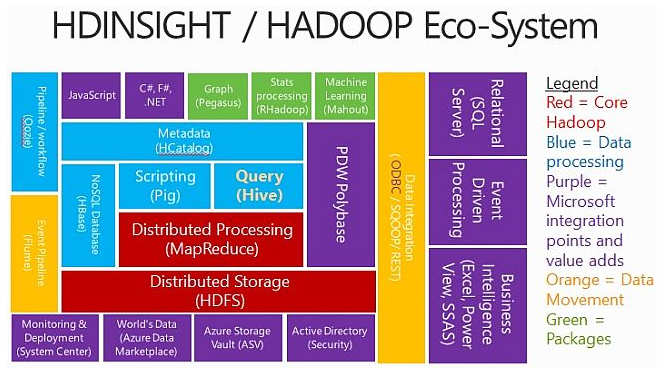
Microsoft Azure is a cloud service provided by Microsoft, and one of the services offered is HDInsight, an Apache Hadoop-based distribution running in the cloud on Azure. Another service offered by Azure is blob storage. Azure Storage functions as the default file system and stores data in the cloud and not on-premises or in nodes. This way, when you are done running an HDInsight job, the cluster can be decommissioned (to save you money) while your data remains intact.

HDinsight provides an excellent scenario for IoT analytics, PoC\Development, bursting of on-Premise resources to the Cloud, etc.
First thing of course what you will need is Microsoft Azure Subscription. Subscription has many moving parts, and http://azure.microsoft.com has interactive pricing pages, a pricing calculator, and plenty of documentation. If you have an MSDN subscription you will get a limited Azure subscription as well (just have to enable and link it) or you can setup a trial subscription at https://azure.microsoft.com/en-us/pricing/free-trial/. For this little tutorial I will be using my MSDN subscription.
Assuming you know how to setup your subscription and can login to Azure Management Portal our next step will be to create Azure storage account. Now I already have number of storage accounts, but will create on just for this tutorial:
Hit +NEW in lower left side of portal and expand your choices, picking storage:

Pick unique URL , data center location and hit Create Storage Account. Easy:

Once the account is created I will create storage container within this account. In your account dashboard navigate to containers tab and hit create new container:

Enter name for container and If there is any chance of sensitive or PII data being loaded to this container choose Private access. Private access requires a key. HDInsight can be configured with that key during creation or keys can be passed in for individual jobs.

This will be the default container for the cluster. If you want to manage your data separately you may want to create additional containers.
Next I will create Hadoop\HDInsight cluster. Here as with a lot of things in Azure I can use either Quick Create or Custom Create options, later giving me more control of course. Lets create an HDInsight cluster using Custom Create option.
Back to +New in lower left corner of the portal:

Obviously pick unique name and storage account that we created in previous step , you also will need to provide a strict password and finally hit Create button. It takes a bit to create a cluster (way faster than setting one up on your own trust me) and while that is happening you will see this:
![]()
Once that is done I can go to Query Console:from the Dashboard for my cluster:

After I enter user name (admin) and password I setup on cluster creation I can see Query Console:

Just for this tutorial I will pick Twitter Trend Analysis sample. In this tutorial, idea is to learn how to use Hive to get a list of Twitter users that sent the most tweets containing a particular word. Tutorial has a sample data set of tweets housed in Azure Blob Storage (that’s why I created storage account and pointed my HDInsight cluster there- wasb://gennadykhdp@gennadykhdpstorage.blob.core.windows.net/HdiSamples/TwitterTrendsSampleData/
First I will create raw tweet table from data:
DROP TABLE IF EXISTS HDISample_Tweets_raw; --create the raw Tweets table on json formatted twitter data CREATE EXTERNAL TABLE HDISample_Tweets_raw(json_response STRING) STORED AS TEXTFILE LOCATION 'wasb://gennadykhdp@gennadykhdpstorage.blob.core.windows.net/HdiSamples/TwitterTrendsSampleData/';
The following Hive queries will create a Hive table called HDISample_Tweets where you will store the parsed raw Twitter data. The Create Hive Table query shows the fields that the HDISample_Tweets table will contain. The Load query shows how the HDISample_Tweets_raw table is parsed to be placed into the HDISample_Tweets table.
DROP TABLE IF EXISTS HDISample_Tweets;
CREATE TABLE HDISample_Tweets(
id BIGINT,
created_at STRING,
created_at_date STRING,
created_at_year STRING,
created_at_month STRING,
created_at_day STRING,
created_at_time STRING,
in_reply_to_user_id_str STRING,
text STRING,
contributors STRING,
retweeted STRING,
truncated STRING,
coordinates STRING,
source STRING,
retweet_count INT,
url STRING,
hashtags array,
user_mentions array,
first_hashtag STRING,
first_user_mention STRING,
screen_name STRING,
name STRING,
followers_count INT,
listed_count INT,
friends_count INT,
lang STRING,
user_location STRING,
time_zone STRING,
profile_image_url STRING,
json_response STRING);
FROM HDISample_Tweets_raw
INSERT OVERWRITE TABLE HDISample_Tweets
SELECT
CAST(get_json_object(json_response, '$.id_str') as BIGINT),
get_json_object(json_response, '$.created_at'),
CONCAT(SUBSTR (get_json_object(json_response, '$.created_at'),1,10),' ',
SUBSTR (get_json_object(json_response, '$.created_at'),27,4)),
SUBSTR (get_json_object(json_response, '$.created_at'),27,4),
CASE SUBSTR (get_json_object(json_response, '$.created_at'),5,3)
WHEN 'Jan' then '01'
WHEN 'Feb' then '02'
WHEN 'Mar' then '03'
WHEN 'Apr' then '04'
WHEN 'May' then '05'
WHEN 'Jun' then '06'
WHEN 'Jul' then '07'
WHEN 'Aug' then '08'
WHEN 'Sep' then '09'
WHEN 'Oct' then '10'
WHEN 'Nov' then '11'
WHEN 'Dec' then '12' end,
SUBSTR (get_json_object(json_response, '$.created_at'),9,2),
SUBSTR (get_json_object(json_response, '$.created_at'),12,8),
get_json_object(json_response, '$.in_reply_to_user_id_str'),
get_json_object(json_response, '$.text'),
get_json_object(json_response, '$.contributors'),
get_json_object(json_response, '$.retweeted'),
get_json_object(json_response, '$.truncated'),
get_json_object(json_response, '$.coordinates'),
get_json_object(json_response, '$.source'),
CAST (get_json_object(json_response, '$.retweet_count') as INT),
get_json_object(json_response, '$.entities.display_url'),
ARRAY(
TRIM(LOWER(get_json_object(json_response, '$.entities.hashtags[0].text'))),
TRIM(LOWER(get_json_object(json_response, '$.entities.hashtags[1].text'))),
TRIM(LOWER(get_json_object(json_response, '$.entities.hashtags[2].text'))),
TRIM(LOWER(get_json_object(json_response, '$.entities.hashtags[3].text'))),
TRIM(LOWER(get_json_object(json_response, '$.entities.hashtags[4].text')))),
ARRAY(
TRIM(LOWER(get_json_object(json_response, '$.entities.user_mentions[0].screen_name'))),
TRIM(LOWER(get_json_object(json_response, '$.entities.user_mentions[1].screen_name'))),
TRIM(LOWER(get_json_object(json_response, '$.entities.user_mentions[2].screen_name'))),
TRIM(LOWER(get_json_object(json_response, '$.entities.user_mentions[3].screen_name'))),
TRIM(LOWER(get_json_object(json_response, '$.entities.user_mentions[4].screen_name')))),
TRIM(LOWER(get_json_object(json_response, '$.entities.hashtags[0].text'))),
TRIM(LOWER(get_json_object(json_response, '$.entities.user_mentions[0].screen_name'))),
get_json_object(json_response, '$.user.screen_name'),
get_json_object(json_response, '$.user.name'),
CAST (get_json_object(json_response, '$.user.followers_count') as INT),
CAST (get_json_object(json_response, '$.user.listed_count') as INT),
CAST (get_json_object(json_response, '$.user.friends_count') as INT),
get_json_object(json_response, '$.user.lang'),
get_json_object(json_response, '$.user.location'),
get_json_object(json_response, '$.user.time_zone'),
get_json_object(json_response, '$.user.profile_image_url'),
json_response
WHERE (LENGTH(json_response) > 500);
These queries will show you how to analyze the Tweets Hive table that was created to determine the Twitter users that sent out the most tweets containing the word ‘Azure’. The results are saved into a new table called HDISample_topusers
DROP TABLE IF EXISTS HDISample_topusers;
--create the topusers hive table by selecting from the HDISample_Tweets table
CREATE TABLE IF NOT EXISTS HDISample_topusers(name STRING, screen_name STRING, tweet_count INT);
INSERT OVERWRITE TABLE HDISample_topusers
SELECT name, screen_name, count(1) as cc
FROM HDISample_Tweets
WHERE text LIKE '%Azure%'
GROUP BY name, screen_name
ORDER BY cc DESC LIMIT 10;
Now I will run it all, submit the job and watch the Job History Console:

Finally as data has been inserted into my HDISample_topusers table I can show this data as well:
select * from HDISample_topusers;
And get results
luciasannino ciccialucia1960 1 Valerie M valegabri1 1 Tony Zake TonyZake 1 Sami Ghazali SamiGhazali 1 JOSÈ ADARMES ADARMESJEB 1 Eric Hexter ehexter 1 Daniel Neumann neumanndaniel 1 Anthony Bartolo WirelessLife 1
For more details see – https://azure.microsoft.com/en-us/documentation/articles/hdinsight-use-hive/, https://azure.microsoft.com/en-us/documentation/articles/hdinsight-hadoop-tutorial-get-started-windows/, http://www.developer.com/db/using-hive-in-hdinsight-to-analyze-data.html, http://blogs.msdn.com/b/cindygross/archive/2015/02/26/create-hdinsight-cluster-in-azure-portal.aspx


