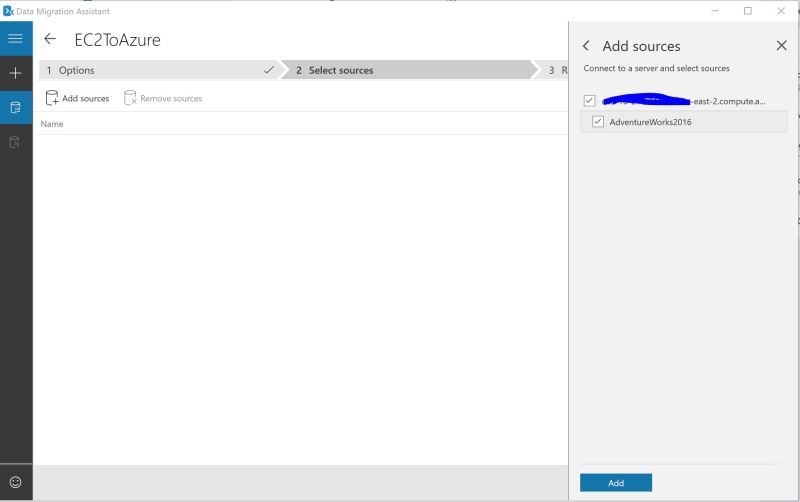
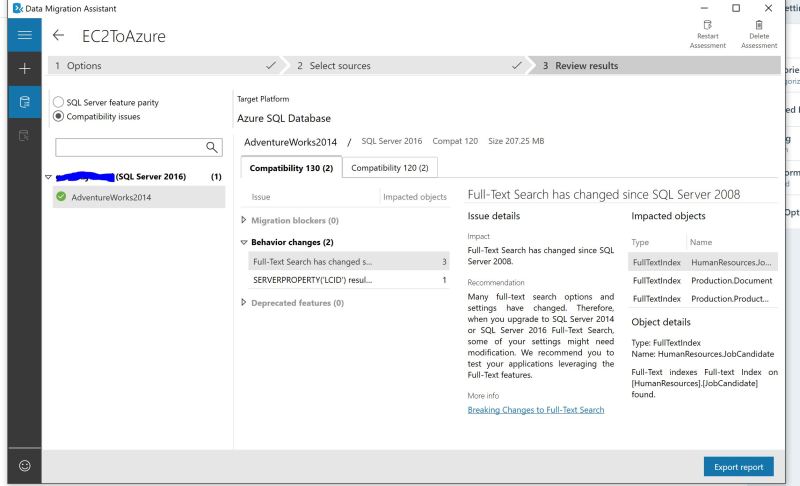
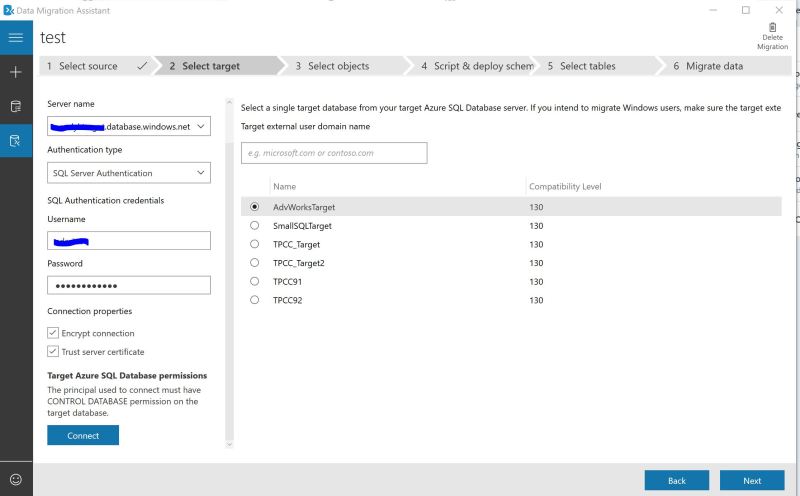
Debezium is a set of open source distributed services to capture changes in your databases so that your applications can see those changes and respond to them. Debezium records all row-level changes within each database table in a change event stream, and applications simply read these streams to see the change events in the same order in which they occurred.
I first came across usefullness of Debezium and Kafka as change streaming platform\mechanism from SQL Server to Azure based on excellent blog posting from SQL Azure PM Davide Mauri I follow in Medium – https://medium.com/@mauridb/sql-server-change-stream-b204c0892641. At that time I was looking for a way to stream Change Data Capture Changes out of SQL Server to Azure Data Lake for number of customers and after reading Davide’s post decided to take a look deeper. Kafka integration (also can be done with Azure Event Hub Kafka message head – https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-create and https://docs.microsoft.com/en-us/azure/event-hubs/event-hubs-kafka-connect-tutorial) allows you to also stream changes to Azure Databricks via Spark Kafka broker for further processing via Spark Streaming:
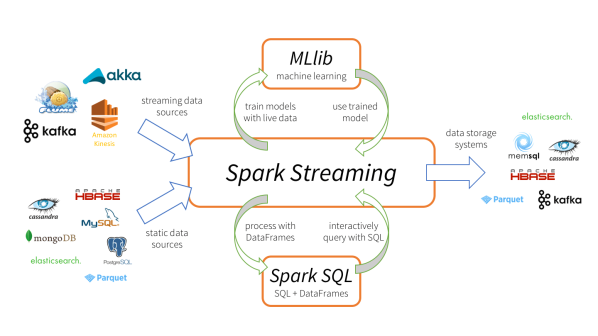
So this opens a lot of opportunities for near real-time data processing of changes from SQL Server without using transactional replication or Service Broker features.
Most commonly, Debezium is deployed via Apache Kafka Connect. Kafka Connect is a framework and runtime for implementing and operating:
- source connectors such as Debezium, which ingest data into Kafka and
- sink connectors, which propagate data from Kafka topics into other systems.
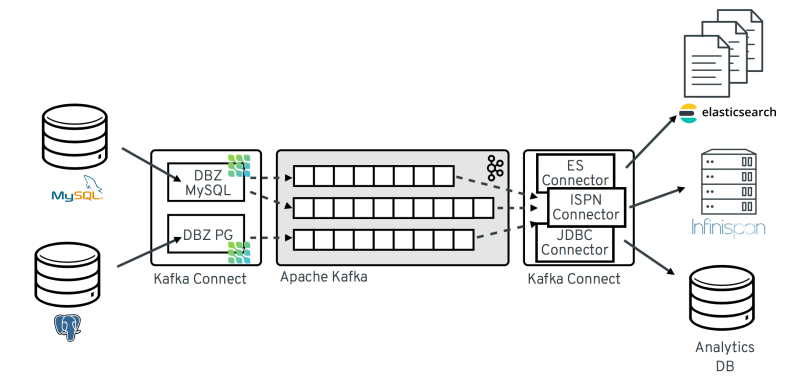
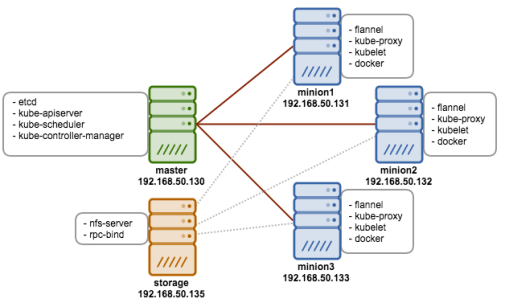
Typical Debezium CDC architecture is shown above with data landing in various sinks like Elastic, Infiniscan or another DB.
Back to Debezium\Kafka setup with SQL Server. How would we set this up based on my last post where I have setup Confluent Cloud Kafka?
Debezium will work with SQL Server Change Data Capture. SQL Server needs to be configured for CDC at a database level. Assuming we have database named demo in our source SQL Server:
USE [demo] GO EXEC sys.sp_cdc_enable_db GO
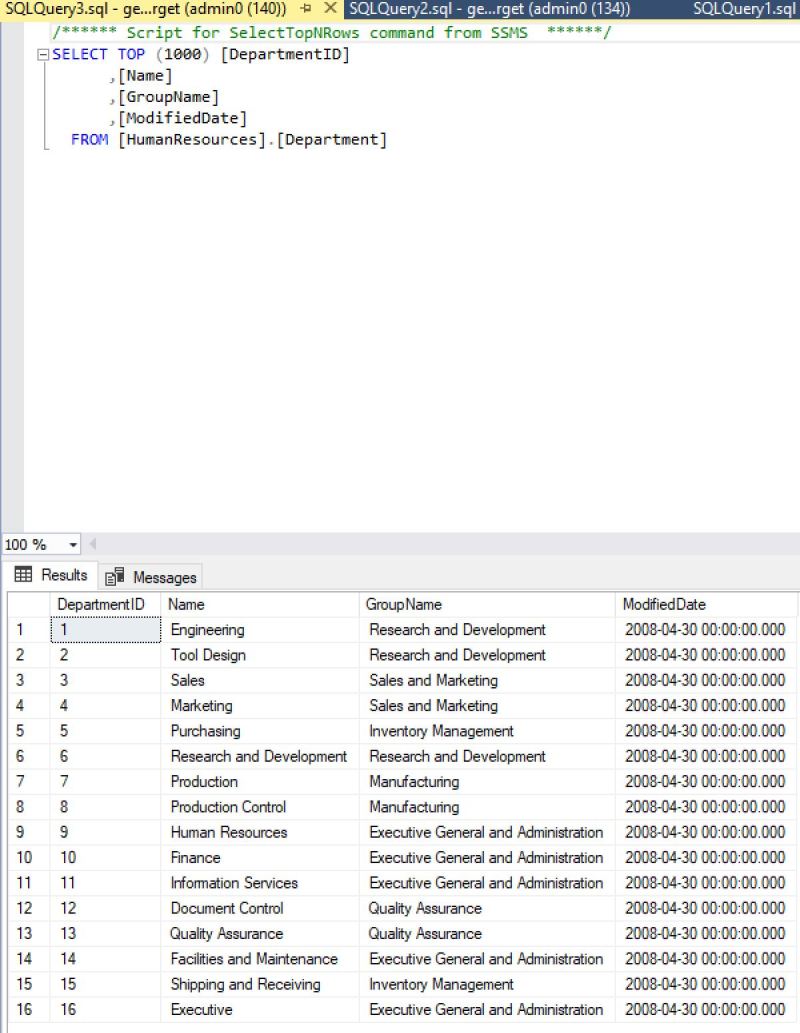
Now lets do it on table level. Assuming we have a table in demo database called orders in that database:
USE [demo] EXEC sys.sp_cdc_enable_table @source_schema = N'dbo', @source_name = N'ORDERS', @role_name = NULL, @supports_net_changes = 0 GO
Verify that user has access to CDC table:
EXEC sys.sp_cdc_help_change_data_capture GO
If results are empty, make sure that the user has privileges to access both the capture instance and CDC tables.
Once that’s done you can setup the connector. To do so you will need confluent-hub installed. I went through following:
- Assuming you already setup Confluent Cloud in Azure as I already blogged about in my last post
- Setup Kafka Connect as explained here – https://docs.confluent.io/current/cloud/connect/connect-cloud-config.html
- Download and install confluent-hub client from – https://docs.confluent.io/current/connect/managing/confluent-hub/client.html .Shocker for me personally was lack of Windows support, looks like client is only available for MacOS and Linux. Had to use my spare old Mac Book.
- Use client to install Debezium SQL Server connector in your Kafka Connect worker.
- Restart worker.
confluent-hub install --no-prompt debezium/debezium-connector-sqlserver:0.10.0
Now, check that plugin has been loaded successfully:
$ curl -s localhost:8083/connector-plugins|jq '.[].class'|grep debezium "io.debezium.connector.sqlserver.SqlServerConnector"
Debezium will write to a topic with all of the data from SQL Server. Debezium also needs its own topic for tracking the DDL—and we need to pre-create both these topics:
$ ccloud kafka topic create --partitions 1 dbz_dbhistory.mssql.asgard-01 $ ccloud kafka topic create mssql-01-mssql.dbo.ORDERS $ ccloud kafka topic list
Now create the connector. It’s a bit more verbose because we’re using a secure Kafka cluster and Debezium needs the details passed directly to it:
curl -i -X PUT -H "Content-Type:application/json" \
http://localhost:8083/connectors/source-debezium-mssql-01/config \
-d '{
"connector.class": "io.debezium.connector.sqlserver.SqlServerConnector",
"database.hostname": "mssql",
"database.port": "1433",
"database.user": "sa",
"database.password": "Admin123",
"database.dbname": "demo",
"database.server.name": "mssql",
"table.whitelist":"dbo.orders",
"database.history.kafka.bootstrap.servers": "${file:/data/credentials.properties:CCLOUD_BROKER_HOST}:9092",
"database.history.kafka.topic": "dbz_dbhistory.mssql.asgard-01",
"database.history.consumer.security.protocol": "SASL_SSL",
"database.history.consumer.ssl.endpoint.identification.algorithm": "https",
"database.history.consumer.sasl.mechanism": "PLAIN",
"database.history.consumer.sasl.jaas.config": "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"${file:/data/credentials.properties:CCLOUD_API_KEY}\" password=\"${file:/data/credentials.properties:CCLOUD_API_SECRET}\";",
"database.history.producer.security.protocol": "SASL_SSL",
"database.history.producer.ssl.endpoint.identification.algorithm": "https",
"database.history.producer.sasl.mechanism": "PLAIN",
"database.history.producer.sasl.jaas.config": "org.apache.kafka.common.security.plain.PlainLoginModule required username=\"${file:/data/credentials.properties:CCLOUD_API_KEY}\" password=\"${file:/data/credentials.properties:CCLOUD_API_SECRET}\";",
"decimal.handling.mode":"double",
"transforms": "unwrap,addTopicPrefix",
"transforms.unwrap.type": "io.debezium.transforms.ExtractNewRecordState",
"transforms.addTopicPrefix.type":"org.apache.kafka.connect.transforms.RegexRouter",
"transforms.addTopicPrefix.regex":"(.*)",
"transforms.addTopicPrefix.replacement":"mssql-01-$1"
}'
Now that everything is running from SQL Server -> Debezium-> Confluent Kafka we can now consume it from Kafka as illustrated here – https://forums.databricks.com/questions/27062/how-connect-confluent-cloud-and-databricks.html
Rest is up to you, what do you want to do with data or where to land it.
More information is here:
https://debezium.io/documentation/reference/connectors/sqlserver.html
https://docs.confluent.io/current/connect/debezium-connect-sqlserver/index.html
https://docs.confluent.io/current/connect/managing/confluent-hub/client.html
https://docs.confluent.io/current/quickstart/cloud-quickstart/index.html#cloud-quickstart
Good tutorial on using Kafka endpoints in Event Hub with Debezium Docker from Davide Mauri – https://github.com/yorek/debezium-sql-change-stream
And Apache Kafka with Spark – https://azure.microsoft.com/en-us/resources/videos/build-2018-real-time-data-streams-with-apache-kafka-and-spark/
Hope this was interesting to some of you at least.