Tuning Hive and other Apache components that run in the background to support processing of HiveQL is particularly important as the scale of your workload and database volume increases. When your applications query data sets that constitute a large-scale enterprise data warehouse (EDW), tuning the environment and optimizing Hive queries are often part of an ongoing effort of your team.
Increasingly, most enterprises require that Hive queries run against the data warehouse
with low-latency analytical processing, which is often referred to as LLAP by Hortonworks. LLAP of real-time data can be further enhanced by integrating the EDW with the Druid business intelligence engine.
Hive2 Architecture and Internals.
Before we begin, I am assuming you are running Hive on Tez execution engine. Hive LLAP with Apache Tez utilizes newer technology available in Hive 2.x to be
an increasingly needed alternative to other execution engines like MapReduce
and earlier implementations of Hive on Tez. Tez runs in conjunction with Hive
LLAP to form a newer execution engine architecture that can support faster
queries.
The architecture og Hive2 is shown below:
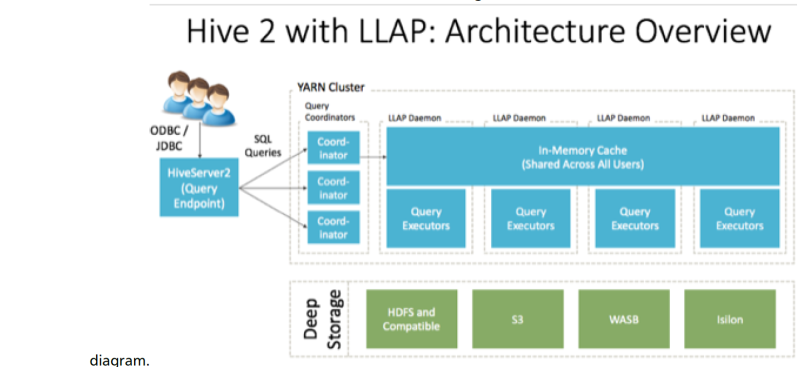
- HiveServer2: provides JDBC and ODBC interface, and query compilation
- Query coordinators: coordinate the execution of a single query LLAP daemon: persistent server, typically one per node. This is the main differentiating component of thearchitecture, which enables faster query runtimes than earlier execution engines.
- Query executors: threads running inside the LLAP daemon
- In-memory cache: cache inside the LLAP daemon that is shared across all users
Tuning Hive cluster memory
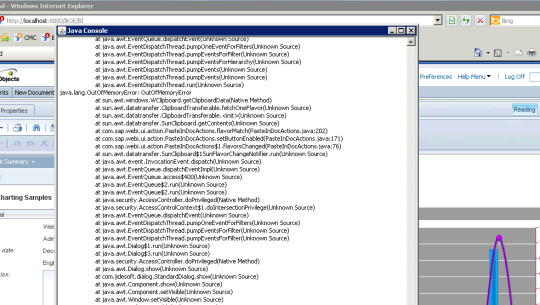
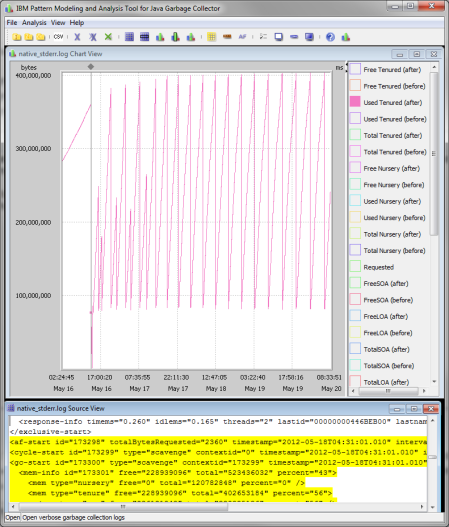
After spending some time hearing from customers about slow running Hive queries or worst yet heap issues precluding successful query execution and doing some research I learned about some important tuning parameters that may be useful for folks supporting Hive workloads. Some of these I will get into below.
To maximize performance of your Apache Hive query workloads, you need to optimize cluster configurations, queries, and underlying Hive table
design. This includes the following:
- Configure CDH clusters for the maximum allowed heap memory size, load-balance concurrent connections across your CDH Hive
components, and allocate adequate memory to support HiveServer2 and Hive metastore operations. - Review your Hive query workloads to make sure queries are not overly complex, that they do not access large numbers of Hive table partitions,
or that they force the system to materialize all columns of accessed Hive tables when only a subset is necessary. - Review the underlying Hive table design, which is crucial to maximizing the throughput of Hive query workloads. Do not create thousands of
table partitions that might cause queries containing JOINs to overtax HiveServer2 and the Hive metastore. Limit column width, and keep the
number of columns under 1,000.
Memory Recommendations.
HiveServer2 and the Hive metastore require sufficient memory to run correctly. The default heap size of 256 MB for each component is
inadequate for production workloads. Consider the following guidelines for sizing the heap for each component, based on your cluster size.

Important: These numbers are general guidance only, and can be affected by factors such as number of columns, partitions, complex joins, and
client activity. Based on your anticipated deployment, refine through testing to arrive at the best values for your environment.
In addition, the Beeline CLI should use a heap size of at least 2 GB.
Set the PermGen space for Java garbage collection to 512 MB for all.
Configuring Heap Size and GC
You can use Cloudera Manager to configure Heap Size and GC for HiveServer2
-
- To set heap size, go to Home > Hive > Configuration > HiveServer2 > Resource Management. Set Java Heap Size of HiveServer2 in Bytes to the desired value, and click Save Changes.
- To set garbage collection, go to Home > Hive > Configuration > HiveServer2 > Advanced. Set the PermGen space for Java garbage collection to 512M , the type of garbage collector used ( ConcMarkSweepGC or ParNewGC ), and enable
or disable the garbage collection overhead limit in Java Configuration Options for HiveServer2. The following example sets the PermGen space to 512M , uses the new Parallel Collector, and disables the garbage collection overhead limit:
-XX:MaxPermSize=512M -XX:+UseParNewGC -XX:-UseGCOverheadLimit - Once you made any changes to Heap and GC you will need to restart. From the Actions drop-down menu, select Restart to restart the HiveServer2 service
Similarly you can set up Heap Size and GC for Hive Metastore with the similar parameters using Cloudera Manager by going tp Home > Hive > Configuration > Hive Metastore > Resource Management.
If you are not using Cloudera Manager or on the HDInsight you can configure the heap size for HiveServer2 and Hive metastore in command line by setting the -Xmx parameter in the HADOOP_OPTS variable to the desired maximum heap size in /etc/hive/hive-env.sh .
The following example shows a configuration with HiveServer2 using 12 GB heap, Hive Metastore using 12 GB heap, Hive clients use 2 GB heap:
if [ "$SERVICE" = "cli" ]; then
if [ -z "$DEBUG" ]; then
export HADOOP_OPTS="$HADOOP_OPTS -XX:NewRatio=12 -Xmx12288m -Xms12288m
-XX:MaxHeapFreeRatio=40 -XX:MinHeapFreeRatio=15 -XX:+UseParNewGC -XX:-
UseGCOverheadLimit"
else
export HADOOP_OPTS="$HADOOP_OPTS -XX:NewRatio=12 -Xmx12288m -Xms12288m
-XX:MaxHeapFreeRatio=40 -XX:MinHeapFreeRatio=15 -XX:-UseGCOverheadLimit"
fi
fi
export HADOOP_HEAPSIZE=2048
You can use either the Concurrent Collector or the new Parallel Collector for garbage collection by passing -XX:+useConcMarkSweepGC or –XX:+useParNewGC in the HADOOP_OPTS lines above. To enable the garbage collection overhead limit, remove the -XX:-UseGCOverheadLimit setting or change it to -XX:+UseGCOverheadLimit .
For more on latest docs on tuning memory and troubleshootng heap\GC exceptions in Hive see Cloudera docs https://docs.cloudera.com/documentation/enterprise/latest/topics/admin_hive_tuning.html or for HDInsight see this great MS docs with configurations – https://docs.microsoft.com/en-us/azure/hdinsight/interactive-query/hive-llap-sizing-guide